Diver Platform®
Diver Platform tilbyr individuelle komponenter eller en komplett løsning for business intelligence. Hver implementering inkluderer installasjonen av alle back-end-servere og produksjonskomponenter. Det er ingen skjulte kostnader eller kostbare tredjepartsverktøy som kreves for tilleggsfunksjoner. Brukere får tilgang til data gjennom en rekke grensesnittalternativer, avhengig av deres informasjon- og analysebehov.
Forenklet data management, governance og analyse
På grunn av sitt unike design overgår Diver andre data management, governance og analyse software produkter. Diver kan fungere med ditt eksisterende datavarehus, men det kreves ikke en underliggende database eller datavarehus. Diver integrerer data fra et ubegrenset antall forskjellige kilder. Brukere kan sammenligne data samlet fra transaksjonssystemer med informasjon i datavarehuset, og ulike datakilder som eksempelvis regneark og flate filer.
Ved bruk av Diver sin minneteknologi, opplever Diver-brukere konsekvent rask responstid, uavhengig av store datamengder.
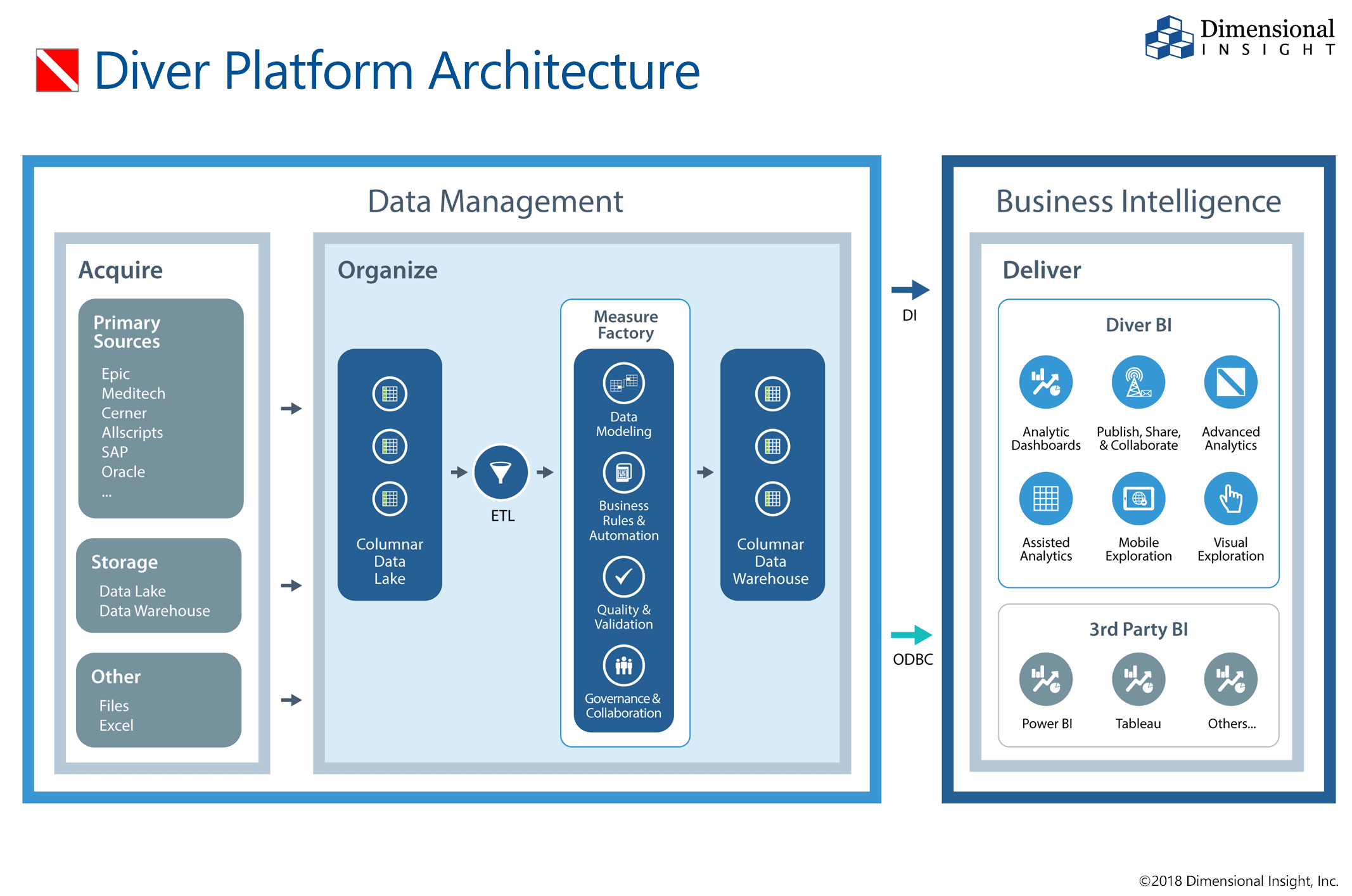
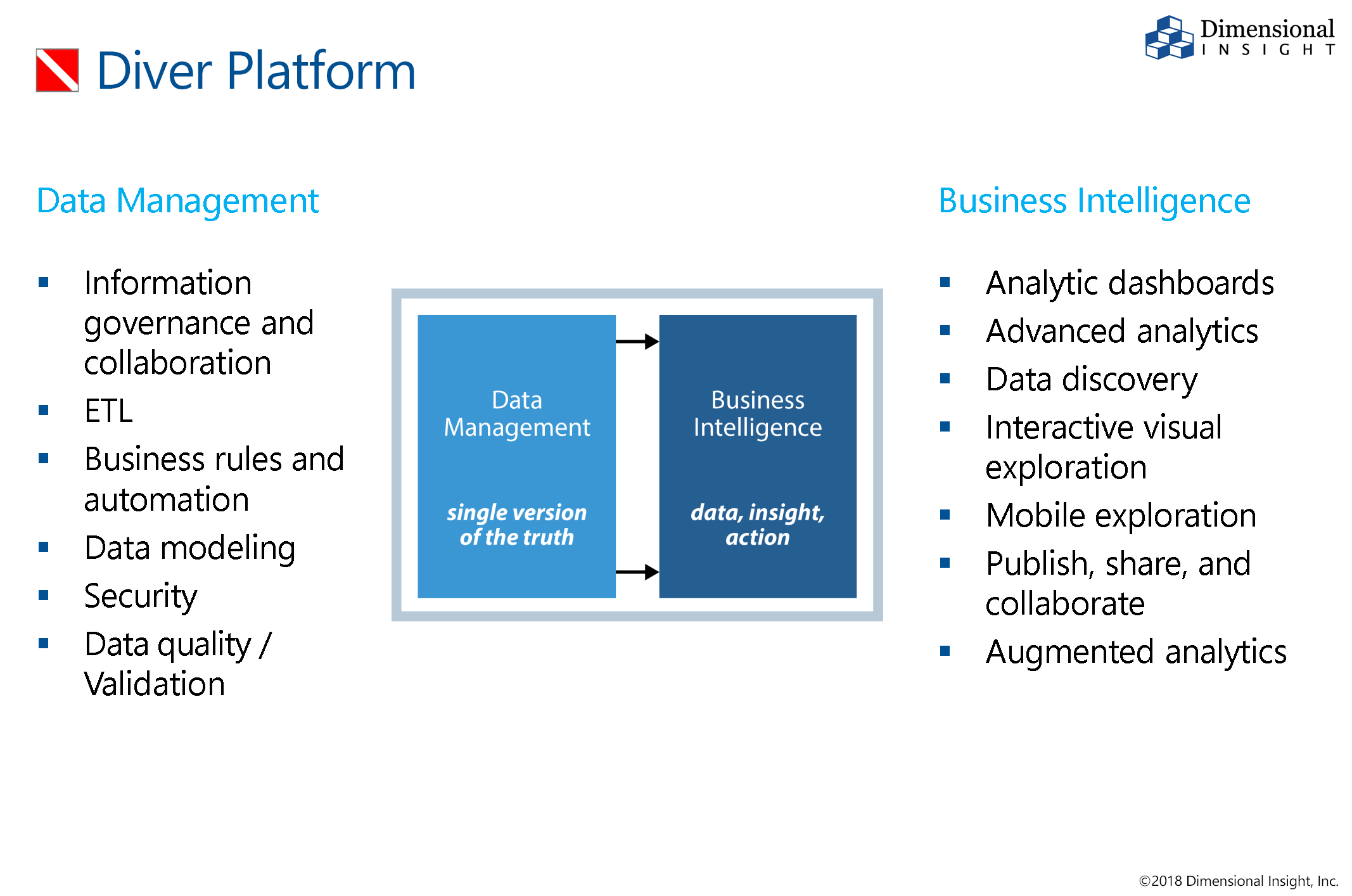
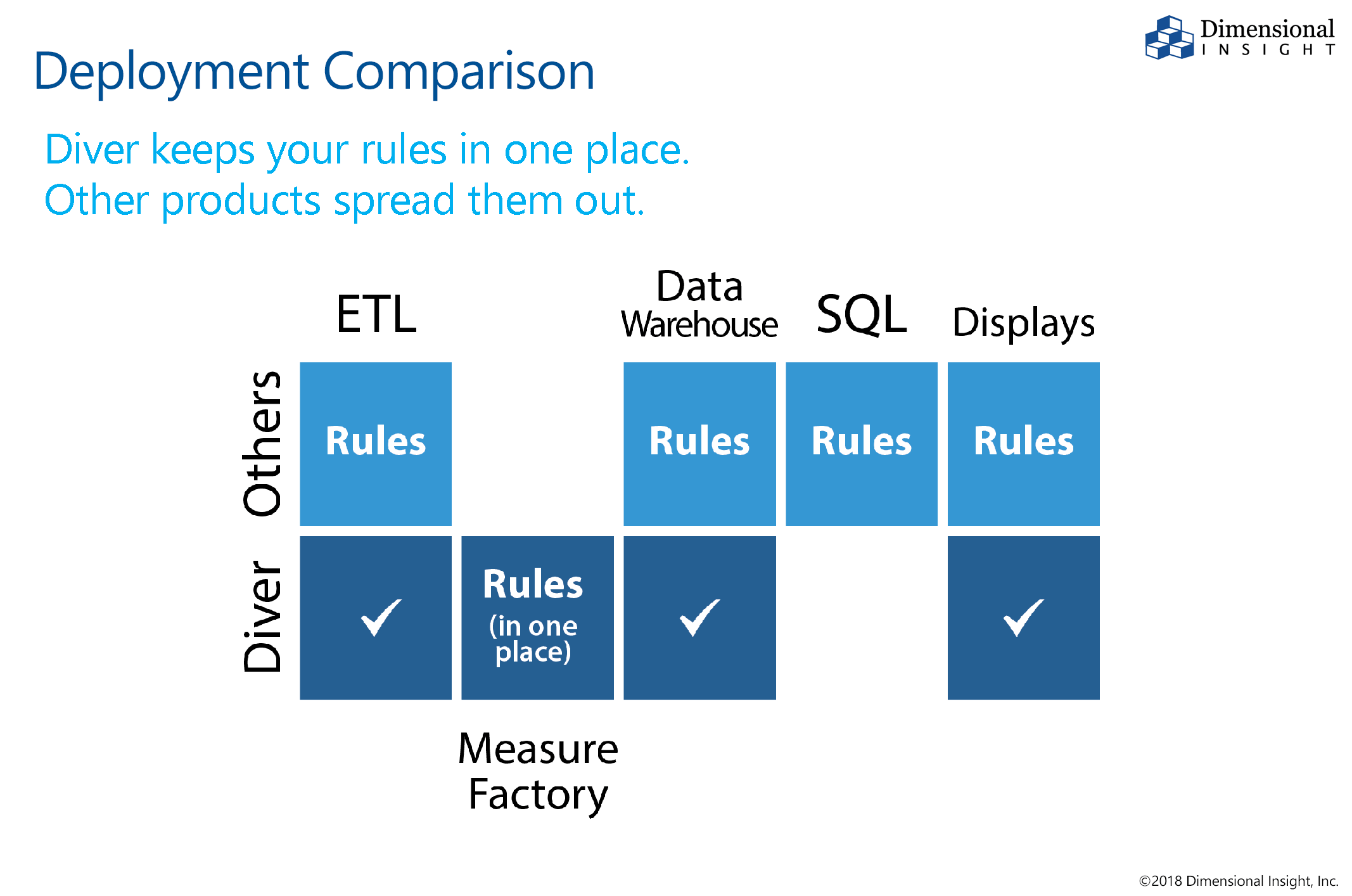
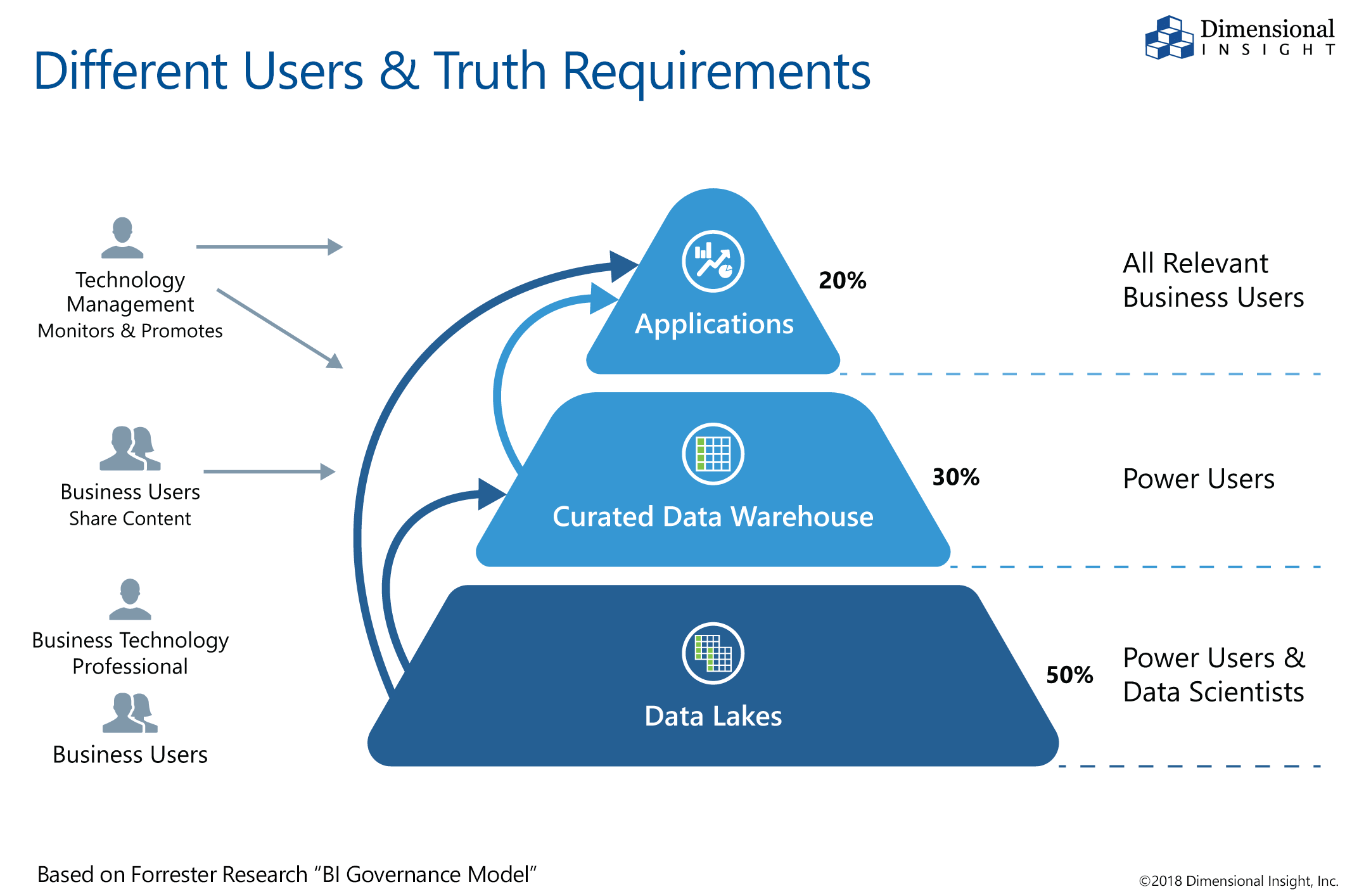
Klikk for større bilde
Lær om hva Diver Platform kan gjøre for deg
Dashboard Funksjoner
- Dykk ned til mer detaljerte data fra hvilken som helst dashboard-indikator
- Identifiser, definer og utvikle beregninger som oppfyller prosjekt-, avdelings- eller organisatoriske informasjonskrav
- Raskt å utvikle og distribuere dashboards som passer til hver brukers rolle og informasjonskrav
- Last ned dashboard indikatorer, diagrammer og data til MS Excel, PowerPoint eller Adobe PDF-dokumenter
Data management og integrasjon
Ekstraksjon, transformasjon og loading (ETL) verktøy gir rask og enkel tilgang til en rekke datakilder:
- Transaksjons databaser
- Flate filer
- ODBC – kompatible databaser
- Microsoft Excel regneark
- Web Service
- Bredt spekter av proprietære dataformater som ERP, EHR og operativsystemer
- Benytt forretningsregler og KPIer med Diver’s Measure Factory
Kraftfull programvare for dataanalyse
- Ingen SQL-queries eller scripting kreves for å utforske og analysere dataene dine
- Flere klienter: Web-basert, frittstående og nettbrett
- Søk, filtrer, sorter, gruppere og eksportere data fra hvilken som helst klient
- En rekke diagramtyper og alternativer hjelper deg med å avdekke skjulte trender og mønstre
- OpenStreetMap, Thunderforest, og Stamen ™ støttes
- Et rikt sett med innebygde funksjoner, inkludert string, math, statistical, and logical
Data governance og sikkerhet
- Fleksible autentiseringsalternativer: Own, System, LDAP, og Web Server
- Dataautorisasjon via tilgangskontroll
- Flere sikkerhetsnivåer og datakryptering
- Tilgangskontroll på datamodell eller feltnivå
- Rollebasert
«Løs oppgaver på egne premisser, samt ha kontroll over data fra datakilde til publisering. Jeg har enda ikke sett et verktøy bedre enn Diver løsningen.»
Bjørn Algrøy, Senior Advisor/Business Intelligence, Bring Logistics, Transport

Big data Engine
Dimensional Insights Diver Platform har en nyutviklet kolonne databaseteknologi som gir økt hastighet og effektivitet. Divers motor for kolonneorientert database er optimalisert for å fokusere mer på søketid enn byggetid. Designet utnytter ny maskinteknologi og ivaretar brukeratferd innen dataanalyse.
KOLONNEBASERT DATABASE DESIGN
Diver® Data Engine bruker en in-memory, kolonnebasert database i binært format. Så hva er egentlig kolonnebasert database teknologi, og hva gjør den så rask?
Vanligvis lagrer en relasjonsdatabase felt i en record, som rader i en tabell. Dette er et bra design når du vil hente alle feltene til en record hver gang den er tilgjengelig. Business intelligence trenger imidlertid vanligvis bare å få tilgang til ett eller noen felt i hver record. For disse søkene er ikke et rad-orienterte designet veldig effektivt.
I det selvindekserende kolonnebaserte database-designet, blir recordene splittet opp i stedet for å lagre alle feltene for hver record sammen. De sammenfallende feltene for alle recordene, eller hver kolonnene i en tabell, blir lagret sammen som blokker i minne. Så hvis du vil utføre kalkuleringer, som for eksempel SUM, MAX, MIN, COUNT, eller AVG, vil bare de relevante kolonnene bli tilgjengelig, noe som gjør utregningen veldig rask.
SKALERBART
Diver® Data Engine er robust konstruert for krevende business intelligence analyse og gir svært god ytelse.
- Databasestørrelse
Diver® Data Engine inneholder ikke separate databaseindekser, slik at diskstørrelsen på den kolonnebaserte cBase er liten i forhold til datamengden. Den håndterer store datamengder i en enkelt cBase modell uten begrensninger på filstørrelse, kolonneantall eller antall dimensjoner. Dette minimerer vedlikeholdsoppgaver i deres BI løsninger.
- Cache
Catched dykk gir rask respons samtidig som du unngår gamle resultater. Som en in-memory data engine, besvarer Diver® Data Engine de fleste spørsmål uten at du trenger tilgang til harddisken, resultatene gjenbrukes og eliminerer kostbare disktilgang.
- Minne
Når Diver® Data Engine laster deler av en cBase inn i minne, kan den dele cBasen over flere prosesser. Flere dykk som kjører samtidig for brukere med forskjellig tilgang deler dette minne, og prosessen sikrer at hver bruker får de riktige resultatene, uten at det går ut over sikkerheten.
- Lave driftskostnader per bruker
Diver® Data Engine gir optimal brukervennlighet med lave inaktive-tilkoblingskostnader per bruker, for å støtte flere brukere samtidig uten en lineær økning i minne. Brukerforbindelsen stenges når operasjonen er fullført, og ressurser er ikke viet til inaktive brukersesjoner.
HASTIGHET
Diver® Data Engine er bygd for hastighet, både for beregninger og bygging, samt har en markant forbedring av responsytelse for klienter og produktiviteten til IT-ansatte.
- Responsytelse
Diver® Data Engines algoritmer optimaliserer responsytelsen for noen av de mest brukte beregningene. Diver® Data Engine kompilerer formler til maskinkode, som er optimalisert for prosessoren og kjøres i maskinkode. Denne optimaliserte design-metodikken minimerer beregningstiden, noe som gjør responsytelsen ekstremt rask.
- Byggetid
Når datamengden din utgjør 500 millioner – 1 milliard rader eller mer, trenger du å minimere byggetiden. Siden Diver® Data Engine ikke utfører forhåndssummerte data, blir byggetidene korte i forhold til datamengden, noe som igjen er med på å få oppdatert data tilgjengelig for brukere raskere og oftere.
EFFEKTIV ADMINISTRASJON
Brukere trenger rask tilgang til informasjon og IT trenger å sikre at de kan administrere og støtte brukerens krav. Diver Platform®s Data Engine har både Workbench® for utviklere og DiveTab® for å holde mobile ansatte tilkoblet når de er på farten.
- Installasjon
Dimensional Insights globale team av business intelligence konsulenter bistår med design, implementering og skreddersyr din applikasjon. Konsulenttjenester gir fleksibilitet til å levere komplette nøkkel-løsninger eller ekstern støtte til ditt interne IT-team. Du kan velge aktuelt servicenivå for deg, som gir deg kontroll over din applikasjon.
- Konsolidere datakilder
Bedrifter ser en økning i mengden og mangfoldet av data i ulike formater fra forskjellige plattformer og det økte behovet for å kombinere ulike grensesnitt. Diver-motoren utnytter det nyeste innenfor maskinvare, for eksempel raskere kjernehastigheter og flere kjerner for innebygd parallell prosessering, stort minne, ny disk teknologi (SSD) og avansert kompilatorteknologi. Alt dette øker ytelsen radikalt.
- Workbench®
Diver®s Workbench®, et integrert utviklingsmiljø (IDE), hjelper utviklere å administrere hele back-end prosessen, fra datakilde til portal. Diver® Data Engine konfigurasjon og script bruker et enkelt tekst-basert scriptspråk, hvilket utviklere har tilgang til og kan redigere med den robuste Workbench®. Scriptspråket er enkelt og kraftfullt for både bygging og dykk. Workbench® gir rask kodeproduksjon med fokus for viktige deler av scriptet, kodeforslag og beskrivende hjelp.
- DiveTab® klient
DiveTab® klienten er drevet av Diver® Data Engine og er en nettbrett-basert mobilteknologi for selvbetjent rapportering og analyse. DiveTab® bidrar til effektiv data-baserte beslutninger og distribusjon av dashboard og rapporter. DiveTab® bruker Diver® Data Engines hastighet for rask og sikker rollebasert tilgang til dine data, dokumenter og annen informasjon. Alt sentralisert og distribuert ved synkronisering.
Hva er «data management»?
Her er BusinessDictionary.com’s definisjon på «data management»:
Administrative process by which the required data is acquired, validated, stored, protected, and processed, and by which its accessibility, reliability, and timeliness is ensured to satisfy the needs of the data users.