Data Analytics und Datenmanagement
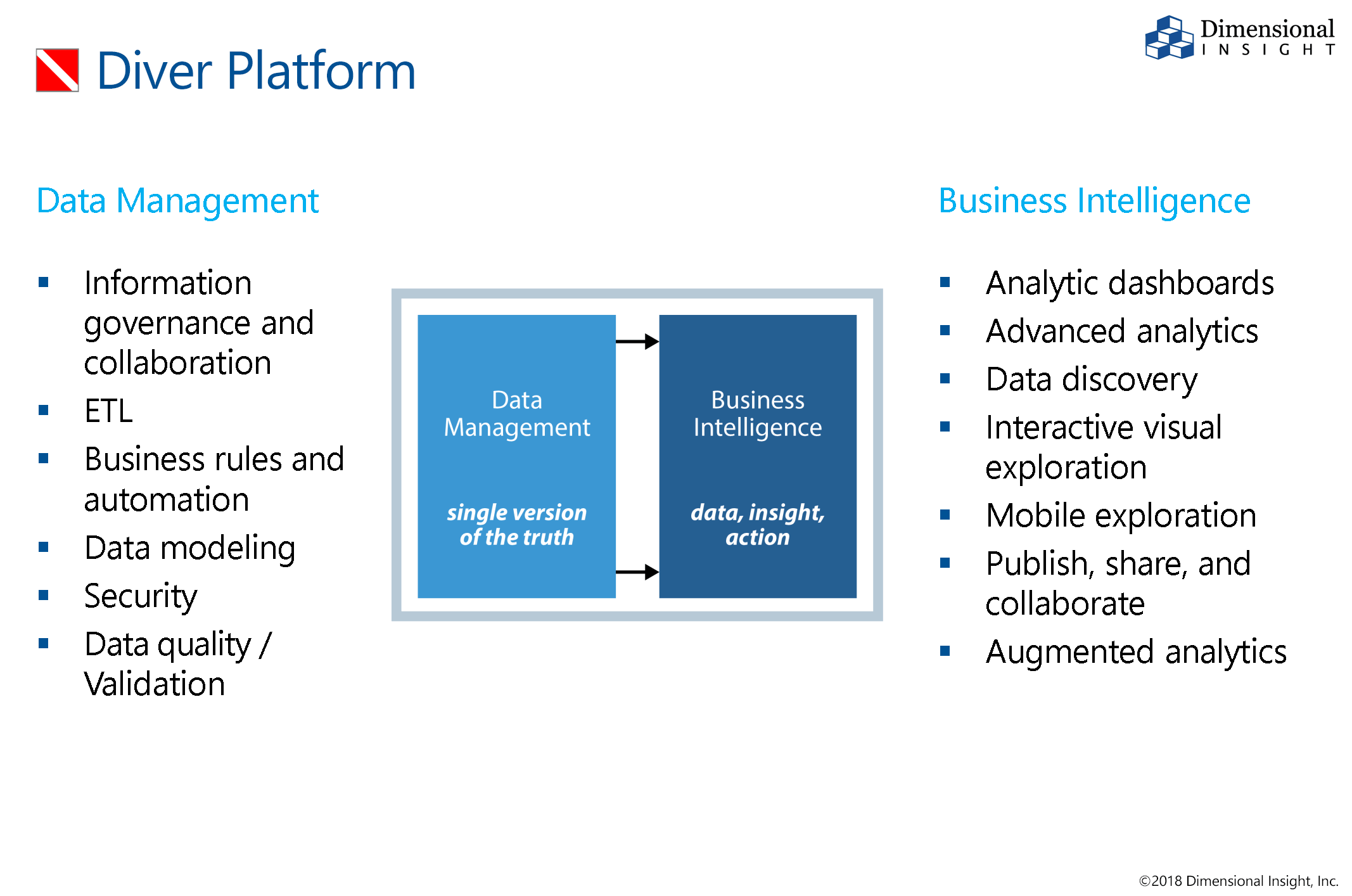
Die Diver Platform bietet einzelne Komponenten oder ein komplettes Business Intelligence-Lösungsset. Bei jeder Implementierung werden alle Back-End-Server- und Produktionskomponenten installiert. Es sind keine versteckten Kosten oder teure Tools von Drittanbietern erforderlich, um zusätzliche Funktionen bereitzustellen. Benutzer greifen über eine Reihe von Schnittstellenoptionen auf die Daten zu, abhängig von ihren spezifischen Anzeige- und Analyseanforderungen.
Datenmanagement, Governance und Analytics vereinfacht
Aufgrund seines einzigartigen Designs übertrifft Diver Platform ™ andere Softwareprodukte für Datenverwaltung, Governance und Analyse. Diver® kann mit Ihrem vorhandenen Data Warehouse arbeiten und Daten aus einer beliebigen Anzahl unterschiedlicher Quellen integrieren. Benutzer können Daten, die aus Transaktionssystemen gesammelt wurden, mit Informationen im Data Warehouse und älteren Datenquellen oder Tabellenkalkulationen und flachen Dateien vergleichen.
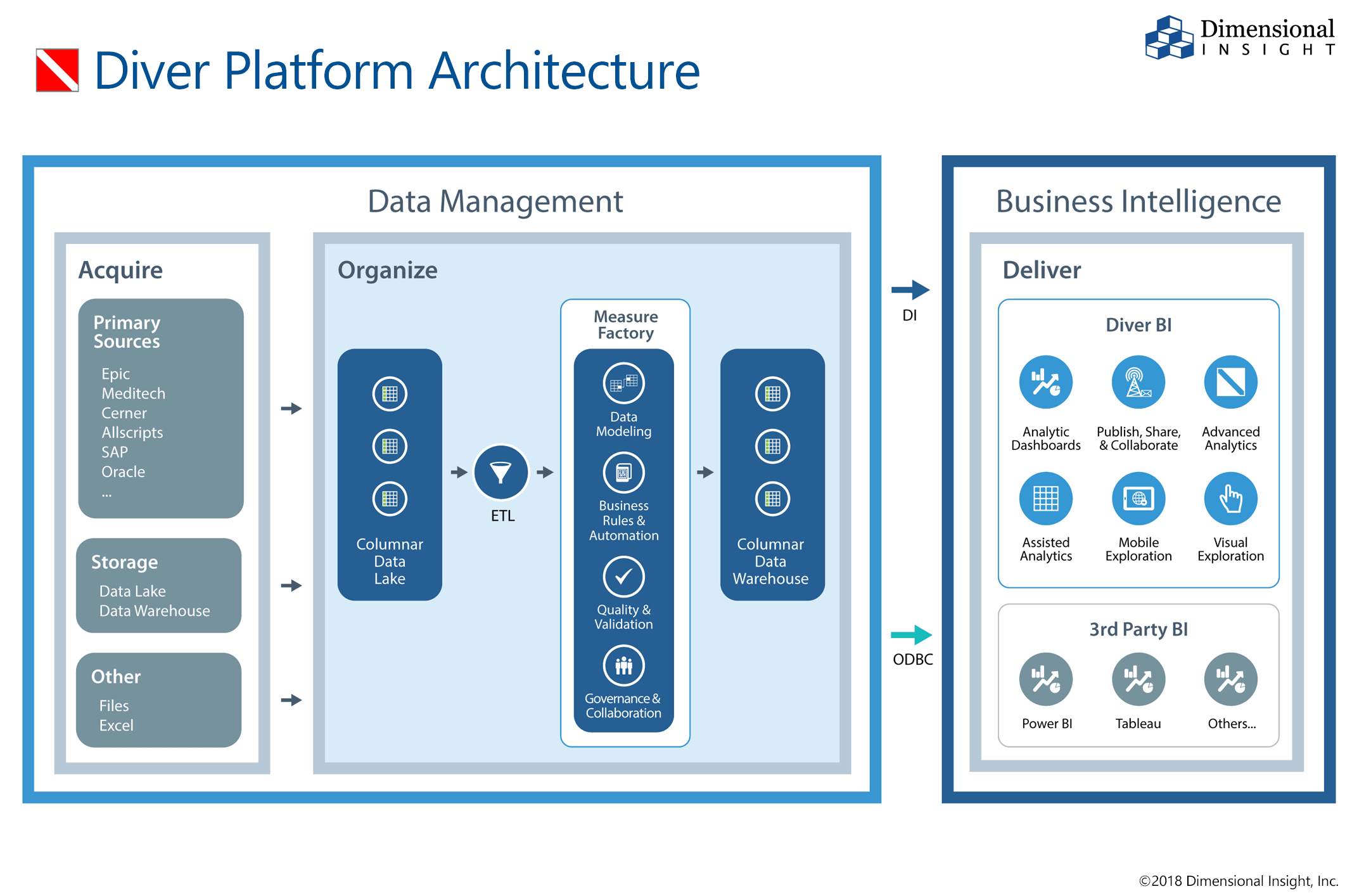

klicken um zu vergrößern
Erfahren Sie mehr über den Datenverwaltungsprozess von Diver Platform®.
Dashboard-Funktionen
- Vordefinierte Bohrpfade sind bei Diver® nicht erforderlich. Führen Sie aus jedem Dashboard-Indikator detaillierte Daten hinzu
- Identifizieren, definieren und entwickeln Sie Metriken, die den Anforderungen von Projekten, Abteilungen oder Organisationsinformationen entsprechen.
- Entwickeln und Bereitstellen von Dashboards, die den Jobrollen und Informationsanforderungen der einzelnen Benutzer entsprechen
- Laden Sie Dashboard-Metriken, Diagramme und Daten in MS Excel®-, PowerPoint®- oder Adobe® PDF-Dokumente herunter
Datenmanagement und Integration
Das Tool zum Extrahieren, Transformieren und Laden (ETL) bietet schnellen und einfachen Zugriff auf eine Vielzahl von Datenquellen:
- Transaktionsdatenbanken
- Flache Dateien
- ODBC-kompatible Datenbanken
- Microsoft® Excel®-Tabellenkalkulationen
- Breite Palette proprietärer Datenformate wie ERP, EHR und Betriebssysteme
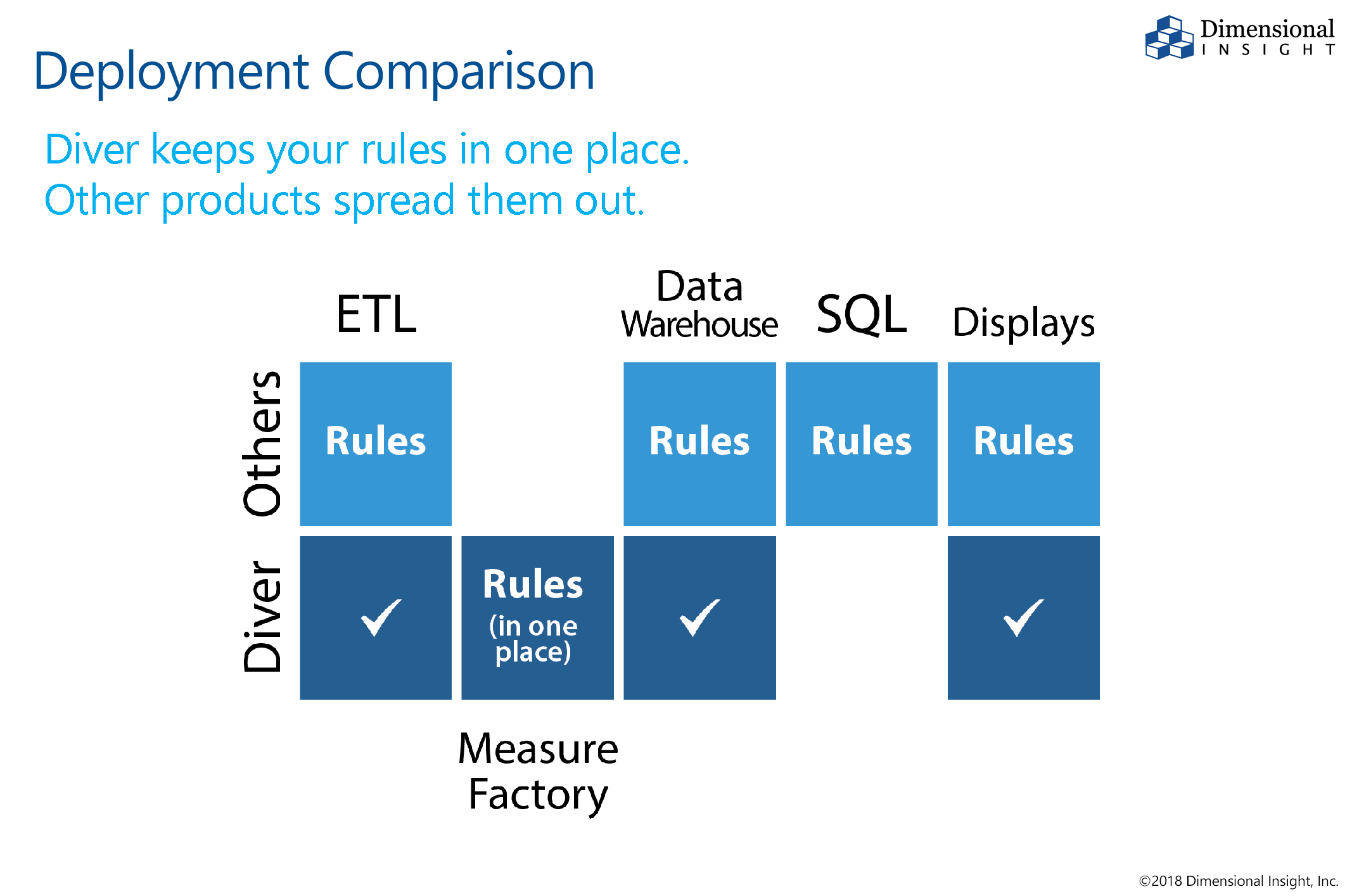
- Wenden Sie Regeln und Maßnahmen mit Diver® Measure Factory® an
Leistungsfähige Datenanalyse-Software
- Es sind keine SQL-Abfragen oder -Skripts erforderlich, um Ihre Daten zu untersuchen und zu analysieren
- Mehrere Clients: Webbasiert, Desktop, Tablet
- Suchen, filtern, sortieren, gruppieren und exportieren Sie Daten von einem beliebigen Client aus
- Dutzende Diagrammtypen und -optionen helfen Ihnen, verborgene Trends und Muster aufzudecken
- Unterstützung für OpenStreetMap, Thunderforest und Stamen ™
- Zahlreiche integrierte Funktionen, einschließlich Zeichenfolge, Mathematik, Statistik und Logik
Data Governance und Sicherheit
- Flexible Authentifizierungsoptionen: Eigene, System, LDAP und Webserver
- Datenautorisierung über zugewiesene Eigenschaften und Zugriffssteuerungsregeln
- Mehrere Sicherheitsstufen und robuste Datenverschlüsselung
- Zugriffskontrolle auf Datenmodell- oder Feldebene
“In der Lage zu sein, Informationen anzuzeigen, die den Benutzer sofort zu einer Schlussfolgerung führen, ist sehr leistungsfähig.”
Jim Staton, Vizepräsident, Informationstechnologie / Gegenseitiges Verteilen, Getränke-Alkoholindustrie

Big Data Processing Engine
Diver Platform® von Dimensional Insight, komplett überarbeitete, kolumnare Datenbanktechnologie für höchste Geschwindigkeit und Effizienz. Das spaltenorientierte, gemeinsam nutzbare Datenbankspeicherformat von Diver´s® Data Processing Engine ist für Abfragezeitberechnungen anstelle von Buildzeitberechnungen optimiert. Das Design nutzt Hardwareinnovationen und Analyseverfahren, um das Benutzerverhalten und die Abfragen besser zu handhaben.
Spalten-Datenbank-Design
Die Datenverarbeitungs-Engine von Diver’s® verwendet eine In-Memory-Säulendatenbank im Binärformat. Also, was ist säulenartige Datenbanktechnologie und was macht sie so schnell?
Normalerweise speichert eine relationale Datenbank Felder nacheinander wie Datensätze in einer Tabelle in einem Datensatz. Dies ist ein hervorragendes Design, wenn Sie bei jedem Zugriff auf den Datensatz alle Felder eines Datensatzes abrufen möchten. Business Intelligence-Abfragen müssen jedoch normalerweise nur auf ein oder einige Felder jedes Datensatzes zugreifen. Für diese Abfragen ist das zeilenorientierte Design nicht sehr effizient.
Anstatt die Felder für jeden Datensatz zusammen zu speichern, werden die Datensätze beim selbstindizierenden, spaltenförmigen Datenbankdesign getrennt. Die Like-Felder für alle Datensätze oder jede Spalte einer Tabelle werden zusammen in Speicherblöcken gespeichert. Wenn Sie nun Berechnungen an den Daten durchführen möchten, z. B. SUMME, MAX, MIN, COUNT oder AVG, wird nur auf die relevanten Spalten zugegriffen, wodurch die Berechnungen sehr schnell erfolgen.
SKALIERBARKEIT
Skalierbarkeit
Diver’s® Data Processing Engine-Design ist robust genug für anspruchsvolle Business-Intelligence-Analysen und liefert eine schnelle Leistung, ohne Ressourcen zu belasten.
Datenbankgröße
Die Datenverarbeitungs-Engine von Diver verwaltet keine separaten Datenbankindizes, sodass die Größe der kollektorbasierten cBase auf der Festplatte im Verhältnis zur Dateneingabe gering ist. Es verarbeitet große Datenmengen in einer einzigen cBase ohne Begrenzung der Dateigröße, Spaltenanzahl oder Anzahl der Dimensionen, wodurch Wartungsaufgaben minimiert werden.
Zwischenspeicher
Zwischengespeicherte Tauchgänge bieten eine schnelle Reaktion und vermeiden veraltete Ergebnisse. Als In-Memory-Daten-Engine beantwortet die Diver’s® Engine die meisten Abfragen, ohne auf die Festplatte zugreifen zu müssen, speichert die Ergebnisse für die Wiederverwendung und eliminiert kostspielige Festplattenzugriffe.
Erinnerung
Wenn die Diver’s Engine Teile einer cBase in den Speicher lädt, kann sie die cBase über mehrere Engineprozesse hinweg gemeinsam nutzen. Mehrere Tauchgänge, die gleichzeitig für Benutzer mit unterschiedlichen Zugriffsrechten ausgeführt werden, teilen diesen Speicher. Die Engine-Prozesse stellen sicher, dass jeder Benutzer die richtigen Ergebnisse erzielt, ohne die Sicherheit zu beeinträchtigen.
Geringer Aufwand pro Benutzer
Diver’s Data Engine bietet eine schnelle Benutzerleistung mit niedrigen Verbindungskosten pro Benutzer, um mehr gleichzeitige Benutzer zu unterstützen, ohne dass der Speicher und die Prozessorauslastung linear zunehmen. Benutzerverbindungen werden geschlossen, wenn der Vorgang abgeschlossen ist, und Ressourcen werden nicht für leere Benutzersitzungen verwendet.
GESCHWINDIGKEIT
Diver’s® Data Engine ist auf Geschwindigkeit ausgelegt, sowohl für Berechnungen als auch für Builds. Dadurch wird die Laufzeitleistung für Kunden und die Produktivität der IT-Mitarbeiter erheblich gesteigert.
Laufzeitleistung
Diver’s® Data Engine-Algorithmen optimieren die Laufzeitleistung für einige der am häufigsten verwendeten Berechnungen. Die Diver’s®-Berechnungs-Engine kompiliert Formeln in Maschinencode, der für den Prozessor optimiert ist, auf dem sie ausgeführt wird, und der Maschinencode wird roh ausgeführt. Diese Designoptimierungen reduzieren die Verarbeitungszeit der Berechnungen und machen die Laufzeitleistung extrem schnell.
Baue mal
Wenn Ihre Dateneingabe 500 Millionen beträgt – 1 Milliarde Zeilen oder mehr, benötigen Sie Builds, um schnell umzukehren. Diver’s® Data Engine fasst die Daten nicht im Voraus zusammen. Daher sind die Build-Zeiten der Engine im Verhältnis zur Dateneingabe gering, was dazu führt, dass aktuelle Daten schneller und häufiger für Benutzer verfügbar sind
MANAGIERBARKEIT
Verwaltbarkeit
Benutzer benötigen einen schnellen Informationszugriff und IT-Anforderungen, um sicherzustellen, dass die Benutzeranforderungen verwaltet und unterstützt werden können. Diver Platform® data engine arbeitet sowohl mit Diver’s® Workbench® für Entwickler als auch mit DiveTab® zusammen, um Ihre mobilen Mitarbeiter unterwegs in Verbindung zu halten.
Installation
Das globale Team der Business Intelligence-Berater von Dimensional Insight unterstützt Sie beim Design, der Implementierung und der Anpassung Ihrer Anwendung. Beratungs-Servicepläne bieten die Flexibilität, komplette interne Lösungen oder Remote-Support für Ihr internes IT-Team oder einen beliebigen Servicelevel bereitzustellen, sodass Sie die Kontrolle über Ihre Anwendung haben.
Datenquellen konsolidieren
Unternehmen auf Unternehmensebene sehen eine zunehmende Menge und Vielfalt von Daten in verschiedenen Formaten auf verschiedenen Plattformen und die zunehmende Notwendigkeit, Ansichten zu kombinieren. Specter nutzt die neuesten Hardwarevoraussetzungen, wie z. B. höhere Core-Geschwindigkeiten und mehrere Cores für integrierte Parallelverarbeitung, große Speicherkapazitäten, Solid State Disk (SSD) und fortschrittliche Compiler-Technologie, um die Leistung in diesen Umgebungen radikal zu steigern.
Workbench®
Diver’s® Workbench®, eine integrierte Entwicklungsumgebung (IDE), unterstützt Entwickler bei der Verwaltung des gesamten Back-End-Prozesses von der Datenquelle bis zum Portal. Die Diver’s Data Engine-Konfiguration und -Skripts verwenden eine einzige textbasierte Skriptsprache, auf die Entwickler mit dem robusten Workbench®-Editor zugreifen und sie bearbeiten können. Die Skriptsprache ist für Builds und Tauchgänge einfach und leistungsstark. Workbench® beschleunigt die Entwicklung mit Highlights für wichtige Teile des Skripts, Codevorschlägen und einer beschreibenden Hilfe.
DiveTab®-Client
Der DiveTab®-Client basiert auf der Daten-Engine von Diver und ist eine tablet-basierte mobile Technologie für Self-Service-Berichte und -Analysen, die die datengesteuerte Entscheidungsfindung und die Bereitstellung von Informationen mithilfe von Dashboards unterstützt. DiveTab® nutzt die Geschwindigkeit der Diver’s® Data Engine, um von einem zentralen Ort aus schnell und sicher auf Ihre Daten und andere Ressourcen wie Präsentationen und Dokumente zuzugreifen.
Was ist “Datenverwaltung”?
Hier ist die Definition von BusinessDictionary.com für “Datenverwaltung”:
Verwaltungsverfahren, durch das die erforderlichen Daten erfasst, validiert, gespeichert, geschützt und verarbeitet werden und durch deren Zugänglichkeit, Zuverlässigkeit und Aktualität sichergestellt wird, dass die Bedürfnisse der Datennutzer erfüllt werden.