 Workbench® Visual Integrator™ (VI) biedt een brede ondersteuning voor verschillende types bestandcoderingen. Wanneer je te maken hebt met invoer vanuit verschillende bronnen, dan zal je zeker weten dat je codering overeenkomt met elk bestand dat wordt opgepakt. Kijk alleen al naar een VI invoer object en zie dat het de volgende coderingen ondersteund: auto, ascii, gb 18030, latin1, utf-8, unicode, unicode-be, and unicode-le. Vanzelfsprekend ondersteunen Builder™ en Spectre™ deze ook.
Workbench® Visual Integrator™ (VI) biedt een brede ondersteuning voor verschillende types bestandcoderingen. Wanneer je te maken hebt met invoer vanuit verschillende bronnen, dan zal je zeker weten dat je codering overeenkomt met elk bestand dat wordt opgepakt. Kijk alleen al naar een VI invoer object en zie dat het de volgende coderingen ondersteund: auto, ascii, gb 18030, latin1, utf-8, unicode, unicode-be, and unicode-le. Vanzelfsprekend ondersteunen Builder™ en Spectre™ deze ook.
Toegegeven, dit onderwerp is nogal geeky, maar wekt het je interesse om in de esoterische geschiedenis van de digitale bestandscodering te duiken? Wat zijn al deze opties? En, welke kies je? Om deze vragen te beantwoorden en te begrijpen waarom verschillende soorten codering worden gebruikt en om met vertrouwen de juiste keuzes voor je data te maken, zullen we toch echt moeten beginnen bij het begin.
In het begin…
Iedere tekst in digitale vorm heeft de een of andere codering, een vertaling van de bits en bytes in het bestand naar feitelijke letters en cijfers. Op zichzelf is een serie bytes zonder betekenis, tenzij de code ervoor gegeven evident is.
In het digitale begin was de behoefte aan te coderen letters maar erg klein: alleen de letters van het Latijnse alfabet en zelfs alleen hoofdletters. Die pasten allemaal in de 8 bits van een byte. Een van de eerste codering was EBCDIC, ontwikkeld door IBM, uit het begin van de 60-er jaren van de vorige eeuw (net als ik). Het ziet er erg ongewoon uit, als je gewend bent aan ASCII, maar vandaag de dag is het nog steeds in gebruik in Mainframes en de AS/400. De code verdeelde het byte in tweeën, waarbij in de ene helft de variant werd opgeslagen en in de andere het karakter zelf.
Later kwam ASCII op de proppen (of ANSI in Microsoft terminologie). Het gebruikte 7 bits van een byte, het eerste was altijd 0. Dus decimaal gesproken waren de codes 0-127 in gebruik. Als het eerste bit op 1 stond (128-255) werd het Extended ASCII genoemd. Bij het begin werden deze ‘hoge’ ASCII waarden het tehuis van speciale tekens als Ç en symbolen als
![]()
die programmeurs in staat stelden om alle schermen te tekenen, voor de komst het ‘grafische scherm’. En zelfs deze tekens zijn niet geheel gefossiliseerd, vandaag de dag.
Maar, met de komst van grafische interfaces onder andere, kwam de ‘zolder’ van de ASCII tekens vrij en sommigen gebruikten dat om andere tekens op te slaan zoals het Griekse of Russische alfabet. Dat wil zeggen, opslaan is niet helemaal correct. Wat daar stond was nog steeds 128, bijv, maar nu betekende dat niet meer wat het altijd had betekend. Het kon worden opgevat als een Alpha en niet alleen Ç.
Code Pages
Na verloop van tijd kwamen er meerdere ‘sets van betekenissen’ die konden worden toegekend aan het extended gedeelte van een ASCII waarde, en ze werden Code Pages genoemd. Ze veranderden de waarde niet van de bytes in een computerbestand, maar die bestanden werden anders weergegeven door interface systemen.
De Code Pages werden gestandaardiseerd en ze kregen namen en nummers. Meerdere keren. Er zijn CP-nummers, ISO nummers en namen als het bekende latin1 ofwel ISO 8895-1 ofwel CP1252 (ongeveer). Deze latin1 code pagina gebruikt maar een beperkt bereik van mogelijk bits en in de ‘zolder’ zijn diacritische teken-combinaties opgenomen die veel gebruikt worden in Europese spellingsystemen (niet talen!), inclusief letters als Þ en ß.
Hoe handig en eenvoudig in gebruik het Code Page systeem ook was, er kleefde een aantal problemen aan. Op de eerste plaats was het erg lastig om bijvoorbeeld Greeks en Hebreeuwse letters in dezelfde tekst op te slaan (erg lastig als je Bijbelgeleerde bent), of Russisch en Grieks, waar vast ook iemand last van had… Maar ernstiger, geen enkel spellingsysteem dat niet alfabetisch was paste erin. Syllabische en meer nog woord-schrift systemen (Japans, Chinees) hebben veel te veel tekens om uit te kunnen drukken in 8 bits. Dus was een nieuwe aanpak (en nog meer ISO nummers) op zijn plaats en Unicode deed zijn intrede.
Unicode
De naam Unicode is op zich verwarrend: Het is nl geen code in die zin, dwz geen encoderings systeem (‘hoe schrijf ik het in bits’). Maar het is een lijst. Een heel erg lange lijst van karakters, die begint bij 0 en doorgaat alsof het allemaal niks kost.. De nummers in de lijst worden Code Points genoemd. Een werkelijk fantastische lijst kan worden gevonden op de prachtige website https://unicode-table.com/en/ die groepen karakters ook verbindt aan spellingssystemen en aan de talen waarvoor die gebruikt worden en ook nog waar ter wereld.. Onder mijn favorieten bevinden zich Spijkerschrift, Egyptische Hiërogliefen en het nog altijd niet ontcijferde Linear A schrift uit Kreta, uit het 2e millenium voor Christus. Maar ja zo ben ik.. De lijst is niet bevroren en verandert. We zitten nu op versie 11.0 en je kunt een paperback bestellen van de specificatie…
Encoding
Neem nu eens de glyph ![]() , met de betekenis ‘roepen’ als ik goed ben ingelicht. Het is Code Point x1301E of decimaal 77854 in de Unicode lijst. Hoe kunnen we dit getal nu opslaan in een bestand? Uiteraard past het niet in een byte. Maar hoe slaan we de bits 0001-00110000-00011110 op? We kunnen niet zomaar drie bytes daarvoor gebruiken, want hoe zie je dan aan de eerste byte dat het deel is van iets groters?
, met de betekenis ‘roepen’ als ik goed ben ingelicht. Het is Code Point x1301E of decimaal 77854 in de Unicode lijst. Hoe kunnen we dit getal nu opslaan in een bestand? Uiteraard past het niet in een byte. Maar hoe slaan we de bits 0001-00110000-00011110 op? We kunnen niet zomaar drie bytes daarvoor gebruiken, want hoe zie je dan aan de eerste byte dat het deel is van iets groters?
Wat nodig was, was een manier om die grote getallen te encoderen in bytes (meer dan één, dat is duidelijk). En wel zo, dat er voor de letter A niet 00.00.00.40 nodig is, maw dat we voor elk teken 4 bytes gebruiken. Zelfs voor de tekens die het vaakst voorkomen. Dat zou niet zo efficient zijn.
UTF-8
Een slimme vondst was UTF-8. Het basisidee daarvan is, dat er één byte wordt gebruikt als het nummer in 7 bits past en een extra 8 bits voor elke stap daarboven. Vandaar UTF-8. Het laat zich raden hoeveel daarvoor gebruikt worden in UTF-16… De reden waarom er 7 bits initieel worden gebruikt is hierin gelegen, dat we één bit nodig hebben om te signaleren dat er meer dan één byte in gebruik is voor het nummer. Het slimme van UTF-8 is, dat de Code Points voor A t/m Z etc volledig samenvallen met de ASCII waarden. Zelfs het begin bit op 0 is hetzelfde. Derhalve kan een tekst in ASCII, zonder extended codes, zonder meer als UTF-8 woren opgevat. Het gerucht gaat, dat het ontwerp van UTF-8 de enige manier was om de Amerikanen over de Unicode-streep te trekken. Immers, het Engels (en zelfs Amerikaans) kan prima uit de voeten met A-Z, zonder allerlei buitenissige letters, nee dank u. Het is ook belangrijk om te beseffen, dat UTF-16 niet alleen met 16 bits, dat is 2 bytes, uitbreidt, het begint ook met 16 bits. Derhalve zou de overgrote meerderheid aan digitale teksten, die uit ‘lagere’ Ascii bestaan twee keer zo veel ruimte in beslag nemen als in UTF-8 (of latin1).
UCS-2
In de tussentijd, terug op kantoor, had men bij Microsoft zo zijn eigen ideeën (“dat internet wordt helemaal niks, let op mijn woorden”). Zij encodeerde de UCS (Universal Coded Character Set), die op dit moment code voor code iedntiek is aan Unicode, in de zgn UCS-2 encoding. Deze lijkt sprekend op UTF-16 met name in dat ze met 16-bits begint. Dit wordt gebruikt door MSSQL en het is de reden waarom het twee keer zo groot is, als een database die UTF-8 gebruikt. In een uiterste poging om voor maximale verwarring te zorgen wordt deze UCS-2 encoding soms … “Unicode” genoemd! Dit is het sufste maatje dat ze hebben. Maar denk niet dat Ome Bill een monopolie heeft op opmerkelijk beslissingen: IBM heeft een Code Page nummer voor …. UTF-8 (1208)! En Diver volgt de gebruikelijke terminologie en gebruikt beide. Maar ik loop op de zaken vooruit.
Collation
Een andere term die gebruikt wordt in verband met character sets en encodings is collation. Dit wordt met name gebruikt in systemen die iets met een tekst doen, bijvoorbeeld sorteren. Databases zijn een grootgebruiker van de term. Het bekende mysql, dat immers van Zweedse origine is in zijn Open Source verleden, gebruikt latin1_swedish_ci als standaard collation. Dat betekent dat bij het sorteren van tekst in een kolom, de byte sets worden opgevat als latin1 ascii, hoofdletter-ongevoelig (ci) en met regels voor speciale Zweedse tekens (ik vermoed Å komt na de A oid). Ik zou niet graag een euro moeten neerleggen voor elke mysql database die deze suffe standaard behouden heeft. Een beetje overbodig, want er zullen er niet veel zijn, die een query als “Select text from MuppetScenario where actor=’Swedish Chef’” moeten ondersteunen..
Encodings in Integrator
Als eerder gezegd ondersteunt Diver, dwz Integrator verscheidene encodings. Het is een opmerkelijke lijst: auto, ascii, gb 18030, latin1, utf-8, unicode, unicode-be, unicode-le.
Endianness
Om met de laatste twee te beginnen, hiervoor moeten we ons terminologie-bereik nog weer wat uitbreiden. Computerbestanden kunnen een zgn BoM (“Special delivery, did you order one”) hebben, een Byte Order Mark, of aanduiding van Byte Volgorde. Een BoM bestaat uit een aantal bytes aan het begin van het bestand, nog vóór de eigenlijke data. In zijn algemeenheid kunnen getallen die uit meer dan één byte bestaan in verschillende volgordes opgeslagen worden. Het decimale 259 wordt opgeslagen in twee bytes, x01 en x03. Het eerste byte is 256 in ‘waarde’ en het tweede 3. Dus de eerste byte is het meest significant, de meeste waarde voor je bit-geld. Om redenen die mij althans niet duidelijk zijn, slaan verschillende processor-families die bytes op in een andere volgorde, dus ofwel met de Meest Significante Byte voorop (Most Significant Byte first – MSB) ofwel de Minst Significante (Least Significant Byte first – LSB). Dus dit nummer 259 wordt door de een als x0103 weergegeven, door de ander als x0301. Het Internet is MSB, zo ook Motorola, Sparc en IBM. Daarentegen zijn Apple en Integ LSB. MSB wordt ook wel Big-endian genoemd (lees als: ‘the Big End comes first’) en LSB Little Endian.
We weten al dat ‘unicode’ in deze context feitelijk UCS-2 betekent en nu weten we ook waar de specifieke unicode-be (Big Endian) en unicode-le (Little Endian) voor staat: Als ooit de unicode setting in Integ een rommeltje inleest en je weet zeker dat de file in UCS-2 is: zoek je heil dan eens bij een van de twee Endians….
We kennen latin1, en ascii (alleen lower ascii, geen extended) en ik geef nu weg, dat GB18030 de officiele code set is van de Volksrepubliek China voor zowel traditionele als vereenvoudigde Chineese karakters. Dat laat alleen nog auto over.
Het afleiden van de encoding
Volgens de manual zet auto “de encoding gebaseerd op de file-in setting en unicode status van andere objecten in dezelfde Task.” Dat lijkt handig, maar er is wat meer over te zeggen. Hiertoe moeten we nog even terug komen op de BoM. Deze Byte Mark vertelt de ontvangende processor niet alleen wat de volgorde van bytes is, maar ook, dat het bestand is geëncodeerd in Unicode (Dwz voor Tekstbestanden. Ik heb 100 jaar geleden een C programma geschreven dat TIFF image files las, byte voor byte. En TIFF files hebben ook een BoM, om aan te geen hoe multi-byte nummers (bijv voor kleuren) waren opgeslagen. Dus ook niet-tekstbestanden kennen BoMs en er zijn geen Code Points voor kleuren, uiteraard.), en met welke encoding. Als het bestand begint met FF FE is het UTF-16 Little Endian en andersom FE FF is het UTF-16 Big Endian. En zo voort. Nu is er iets bijzonders aan de hand met UTF-8. Aangezien het een enkelvoudige byte encoding is, is een BoM in ieder geval niet nodig om een volgorde aan te geven. Maar er is tòch een BoM voor UTF-8 voorgesteld (door Microsoft, EF BB BF), maar die wordt niet breed gedragen en er is heel wat UTF-8 aanwezig op de wereld, die niet alszodanig is getagged (en dat was ook juist de opzet tov ASCII).
Dus: ALS er een BoM is, weten we de encodering. Wat nu als die ontbreekt? Gezien de “syntax” hoe UTF-8 multiple byte overflows uitvoert , zijn er in elk geval een heleboel bit-waarde combinaties die in UTF-8 niet voor kunnen komen. En dus kun je van een BoM-loos bestand heuristisch alleen vast stellen, dat het niet is opgemaakt in UTF-8 en dus waarschijnlijk ASCII is, eventueel ASCII met praatjes.
Afleiden van de Code Page?
Maar wat kunnen we zeggen over de gebruikte Code Page van een bestand, door er naar te kijken? Stel je komt een char(199) in een enkelvoudige byte-context tegen, met ervóór “gar” en er achter “on”, dan is de kans groot dat daar het Franse woord garçon staat en dat de 199 geen Griekse Eta is of wat ook, maar dat latin1 in gebruik is. Maar om nu veilig elke Code Page te voorspellen, heb een compendium aan kennis over de talen van de wereld nodig (niet spellingsystemen alleen), dat nog nooit is samen gesteld in de geschiedenis van computers, of een idiote hoeveelheid geluk. Kies maar.
Het is belangrijk om hier te zeggen, dat Integrator de Code Page niet probeert af te leiden. En feitelijk gezien hoeft dat ook niet. Alhoewel de enige 8-bit Code Page die ondersteund wordt latin1 is, behoeven andere Code Pages geen uitdaging te vormen, zolang het hele systeem maar in de zelfde encoding staat. Voorbeeld: een klant heeft teksten in CP1255 (Hebreeuws). In zekere zin, hoeft Diver dat niet te weten. Of een dimensiewaarde nu gevuld is met “ùìåí” of “שלומ” (shalom), is niet relevant. Onder normale omstandigheden, zal ProDiver aan de system locale vragen hoe de ‘zolder’ letters uit de ASCII set weer te geven. Maar ook in dit geval is het interessant om te converteren naar Unicode, om voorbereid te zijn op een toekomst waarin lettertekens gemixt voorkomen en om exports te maken die voldoen aan een moderne standaard.
De auto setting is niet altijd een slimme keus. Bijzondere oplettendheid is geboden als er meer dan één file (van diverse bron) wordt ingelezen in één File-IN object. Alleen de eerste file doet er namelijk toe. In zijn algemeenheid geldt dat er zowel voor het interpreteren van de data zelf als ook de encoding ervan, geen alternatief is voor ‘Ken uw data’. Vaak zul je bij de bron moeten vaststellen, eenmalig wat de encoding is. En dan geldt de vuistregel: wees zo expliciet mogelijk en verlaat je zo min mogelijk op auto.
Opmerking: er is natuurlijk een verschil tussen het vaststellen dat een serie bytes een bepaald Unicode karakter herbergt en in staat zijn dat teken weer te geven in de interface. Een tekst kan op correcte wijze gedecodeerd worden en toch kleine vierkantjes laten zien ipv dansende Hiëroglyfen, gewoon omdat de FONTS ontbreken om ze weer te geven…
Conversie
Moeten bestanden die verwerkt worden ook worden geconverteerd wat betreft encoding? Het is belangrijk om te beseffen dat conversies in het algemeen alleen ‘omhoog’ kunnen in compelxiteit en niet naar beneden. Dat wil zeggen, niet veilig. Het is niet verstandig om een UTF-8 file te converteren naar single byte ASCII, al gaat dat jaren goed. Totdat een nieuw persoon in de database terecht komt, met een naam die niet volledig gespeld wordt in tekens die in latin1 voorkomen. En denk niet ‘het duurt nog wel even voor wij de Chineese markt betreden’. De wereld is dichterbij dan je denkt, denk alleen al aan namen van mensen niet afkomstig uit West Europa.
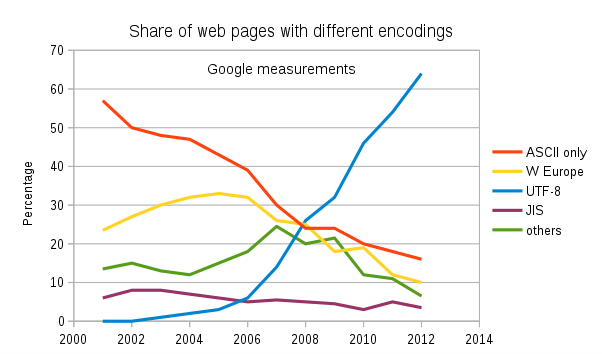 Meer en meer tekst op het internet is in UTF-8 zoals deze Google grafiek duidelijk laat zien. Maar daarbij moeten we aantekenen, dat internet pagina’s behoorlijk vluchtig zijn. Het is een ding om een html pagina in een andere encoding op te slaan. Databases die doorgaans de bron vormen voor de data die in BI systemen wordt verwerkt, neigen niet naar een grote wendbaarheid. De codering daarvan aan te passen vergt doorgaans migratie, soms een nieuwe database. Er zijn nog vele single byte databases (met Zweedse collation) in de wereld…
Meer en meer tekst op het internet is in UTF-8 zoals deze Google grafiek duidelijk laat zien. Maar daarbij moeten we aantekenen, dat internet pagina’s behoorlijk vluchtig zijn. Het is een ding om een html pagina in een andere encoding op te slaan. Databases die doorgaans de bron vormen voor de data die in BI systemen wordt verwerkt, neigen niet naar een grote wendbaarheid. De codering daarvan aan te passen vergt doorgaans migratie, soms een nieuwe database. Er zijn nog vele single byte databases (met Zweedse collation) in de wereld…
Terzijde: als je in Windows een teken als ಸ =3256 = xCB8 in je document wilt invoegen, druk je op de linker Alt toets en tikt dan op het numerieke toetsenbord 03256. De nul is belangrijk. Voor dit soort hoge nummers niet direct, maar Alt+128 is Ç en Alt +0128 €. Merkwaardig. Alt+128 is ASCII, het eerste teken in de Extended Set van de huidige Code Page (latin1) om precies te zijn. Terwijl Alt+0xxxx een Unicode Code Point naar voren tovert. Maar omdat 128—159 zgn. Control Characters zijn in Unicode vormen zij een uitzondering. Op het VS International toetsenbord is deze reeks toegedeeld aan een speciale set tekens zoals het Euro teken. In feite verwijst de Alt+0xxx in deze reeks aan de Windows-1252 Code Page (die bijna gelijk is aan latin1, maar niet gelemaal). Boven de 159 t/m 255 zijn latin1 en 1252 en Unicode identiek. Het Code Point van de EURO is nogal hoog (een relatieve laatkomer, immers. Decimaal 8364) en zo zien we dat Alt+08364 ook een € oplevert. Dus, boven de Alt+0256 zijn we alleen in Unicode Land. Je kunt snel testen welke Code Points ondersteund worden door je huidige Font. Maar wacht, MS Word is hier aan het trucendozen. Toen ik Alt+03256 in tikte, schakelde Word automatisch naar een Font op mijn laptop, die zo’n hoog nummer in zijn rugzak had, nl “Nimala UI”. Slim toch.
De relevantie van deze speciale Alt codes 128-159 is dat Integrator iets vergelijkbaars doet: In het geniep ondersteunt Integ nl CP1252. Het enige verschil met latin1 is dat de laatste bepaalde reeksen niet gebruikt (in het bijzonder 80-9F) en CP1252 wel. Dus, als Integ een teken tegen komt in een zgn latin1 tekst, met een hoge code (bijv 137 ‰), dan wordt deze stilzwijgend omgezet in x2030, zijn Unicode variant. Je kunt het nog simpeler zeggen: latin1 betekent functioneel voor Integ CP1252…
Aanbevelingen
Als vuistregel moet je aanhouden: verlies geen informatie. Als een bron in Unicode is, zoals steeds vaker gebeurt, houd het dan daarin. Integ doet al een interne conversie naar UTF-8. In Workbench is UTF-8 ook de standaard. En daar volgt ook uit: gebruik een unicode versie van Diveline en ProDiver. En save tussenbestanden dan ook in UTF-8. Heel belangrijk bij een migratie van 6.4 naar 7.0: Als er GEEN encoding staat aangegeven bij een File-IN, wordt auto als default gebruikt. Dat betekent in de context van Workbench dat files waar dat vroeger niet zo voor was, nu plots als UTF-8 worden opgevat. Wees dus ook expliciet in de encoding setting en vertrouw niet op een search&replace in .int files, omdat niet overal encoding=auto staat…
Als een bestand wordt aangeleverd in een 8-bit ASCII met een andere Code Page dan latin1 (of 1252), dan kan Integrator de conversie niet doen, (en het zal ook duidelijk zijn dat de interne conversie naar UTF-8 niet klopt). In dat geval moet een externe tool als bijv iconv worden gebruikt. Deze kan gemakkelijk in een Production Extension worden gehuisvest.
Appendix: UTF-8, een technische Case Study
Ooit gezien? Een à zomaar midden in een dimensiewaarde? Bijvoorbeeld de waarde “José”. Uiteraard kan iemand werkelijk Josà hebben bedoeld, een nieuwe Portugese zeep, gevolgd door het copyright teken. Maar eerder zal hier sprake zijn van persoonsverwisseling. Of encodings verwisseling beter gezegd. Laten we eens wat inzoomen in dit voorbeeld. Tot op het bit.
De twee bytes die hier é representeren zijn xC3 en xA9. In bits:
The two bytes represented here by é are xC3 and xA9. Spelled out in bits:

Laten we eens aannemen dat het hier om UTF-8 gaat, kan dat en wat staat er dan? UTF-8 slaat de eerste 128 Code Points (dus karakters met nummer 0-127) in het eerste byte, met het eerste bit op 0. Het eerste bit van à (xC3) is 1, dus het is geen één bytes-teken. Als het Code Point nummer hoger wordt, wordt het volgende byte ook gebruikt, maar hoe?

Deze tabel laat zien hoe de overloop is geregeld. Terwijl een extra byte wel 8 bits oplevert, komen ze toch niet allemaal in aanmerking om getallen op te slaan (de x’en in de tabel). Een vervolg bit krijgt altijd een 1 en een 0 aan het begin. En het eerste byte verandert ook: daar komen meerdere 1’s weer afgesloten met een 0, waarbij het aantal énen staat voor het aantal bytes waar het gehele getal uit bestaat. Met de uitbreiding van één byte komen er effectief slechts 4 bits bij voor de getalshuisvesting. Dat mag teleurstellend zijn, maar je kunt er niet om heen. En voor elke extra byte erbij komen er 5 bits extra voor Code Point Duty. Het grootste Code Point dat zo kan worden opgeslagen in een 4 bytes UTF-8 combinatie is x10FFFF, dwz 1.114.111 en dat is het huidige maximum voor Unicode. Het is niet moeilijk voor te stellen hoe een vijfde extra Byte eruit zou zien. En alhoewel dit systeem een vrij voorspelbaar architectonisch maximum heeft, is het geruststellend om te bedenken dat bij elke extra bit het maximum nummer verdubbeld.
Terug nu naar é. We kunnen zowel de eerste 3 bits van het eerste byte en de eerste twee van het 2e byte identificeren als UTF-8 ‘syntax’.

En dat betekent dat het Code Point getal zelf uit 11 en 101001 bestaat = xE9 of decimaal 233 en dat Unicode Point nummer staat voor “é”. Dus staat er José. Dat lijkt verdedigbaar.
De kans is groot dat bij het lezen van de bron, de encoding op latin1 stond, ipv van utf-8..
- Latin1, Unicode en de Swedish Chef - March 14, 2019
- Big Data en het weer - August 25, 2015
