 Dimensional Insight’s new data engine Spectre reflects the future of business intelligence: it is built on the latest columnar database technology, delivering data analysis faster than ever before. Columnar databases are becoming more and more popular in business intelligence; in fact, a recent survey by Gartner (Oct. 2016) shows that production deployments of columnar/in-memory technology have grown for three straight years.
Dimensional Insight’s new data engine Spectre reflects the future of business intelligence: it is built on the latest columnar database technology, delivering data analysis faster than ever before. Columnar databases are becoming more and more popular in business intelligence; in fact, a recent survey by Gartner (Oct. 2016) shows that production deployments of columnar/in-memory technology have grown for three straight years.
Tweet: Why columnar databases are the future of business intelligence
The idea of a columnar database is not new. In fact, they have been around for years. However, as time has passed they’ve become more and more practical. This is because better support is available and performance has improved over time. Here’s why columnar databases are the future of business intelligence.
Columnar vs. relational databases
Many business intelligence products are built on relational databases. These have served the BI industry well over the years, but do have limitations that can now be overcome with columnar technology.
A standard relational database stores its data in row-major order. In a columnar database, the data is stored in column-major order. This may sound like a small detail, but it has a big impact. Columnar databases allow for a single column to be kept in a continuous chunk of memory, which lets the software take advantage of CPU caches for better performance. With relational databases, users can more easily add or remove rows and the databases can serve as an authoritative source for the data, but columnar databases allow for easier analysis of that data. In short, columnar databases help optimize business.
Columnar databases mean faster analysis
Columnar databases take advantage of hardware to sort and aggregate data in a faster way. They handle reporting better and allow for unlimited columns and dimensions. Values in each column are of the same data type, which allows the data to be highly compressed. When users want to perform calculations, only the relevant columns need to be accessed, resulting in faster calculations.
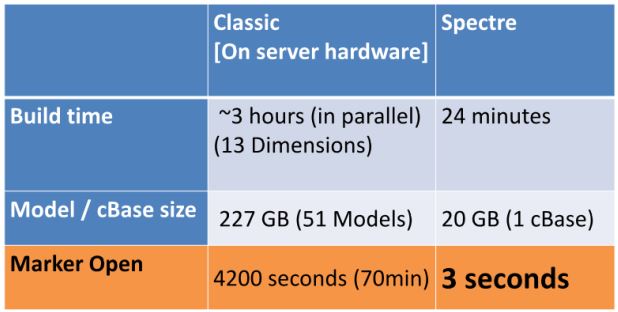
In fact, to see how much faster a columnar database returns results, take a look at the chart below which compares performance of a relational database with our Spectre columnar database. The input is 46 million rows, 215 columns, and 102 GB of text. The output is a 9-dimension multi-tab, six summaries, and 230,000 rows. As you can see, Spectre is much faster.
Why columnar is better for business intelligence
Business intelligence tends to focus on column aggregation – looking at a single column at a time, adding up all of the numbers in that column, counting all of the unique values in that column, organizing the column and finding out where the values change. These are all tasks that a columnar database does better than a relational database. Some databases can include millions of records, and a columnar database allows users to access only the data elements that are relevant to a query. Because of the way the data is organized, columnar databases get results faster and allow for more efficient data analysis.
Spectre, Dimensional Insight’s new data engine built on a columnar database, has advantages over an average columnar database. Next week on the blog, we’ll delve into what those advantages are and why customers should upgrade to Diver Platform 7.0, which includes Spectre technology. Stay tuned.
Related reading

- 3 Reasons You Should Upgrade to Diver Platform 7.0 and Spectre - December 13, 2016
- Why Columnar Databases are the Future of Business Intelligence - December 8, 2016
